
Artykuł w ciągu ostatnich 24 godzin czytało 0 Czytelników
Uwagi i recenzje podręcznika przesyłać na adres wydawnictwa: wydawnictwo@chodor-projekt.net lub leszek.chodor@chodor-pojekt.pl
Podręcznik Imperfekcyjna metoda projektowania konstrukcji [ → Spis treści ]
Dodatek A : Wybrane formuły matematyczne
Dodatek A zawiera materiał dotyczący wybranych zagadnień algebry macierzy, rozwinięcia funkcji wektorowej w szereg Taylora, elementów teorii prawdopodobieństwa i statystyki, charakterystyk wektorów i pół losowych oraz procesów stochastycznych w zakresie umożliwiającym lekturę podręcznika.
Opracowano na podstawie podręczników [1], [2], [3]– dodatki, [4], [5], [6].
Wybrane zagadnienia algebry macierzy
Rozważmy macierz
$$ \begin{equation} [A]=[a_{ij} ]_{(n \times m)} = \left[ \begin{array}{cccc}
a_{11} & a_{12} & \cdots & a_{1n} \\
\vdots& \vdots& \vdots& \vdots& \\
a_{m1} & a_{m2} & \cdots & a_{mn}
\end{array} \right ] _{(n \times m) }\label {1} \end{equation}$$
oraz
$[B]=[b_{ij} ] _{(p \times q)}$
Macierz $[a_{11}, \ldots, a_{mn}]$ dla której, zerowe są wszystkie elementy leżące poza przekątną nazywa się diagonalną $diag [d_1=a_{11},\dots, d_r=a_{mn}]$. Macierz dla której zerowe są wszystkie elementy leżące poniżej lub powyżej przekątnej nazywa się górną trójkątną i odpowiednio dolną trójkątną.
Podstawowe definicje i tożsamości
Iloczyn zwykły $[C]=[c_{ij}]_{(m \times q)} $ macierzy $[A]_{(n \times m)}$ i $[B]_{( p \times q)}$ otrzymuje się w wyniku mnożenia kolumn x wiersze:
$$ \begin{equation} c_{ij}= \sum \limits_{k=1}^n a_{ik} \cdot b_{kj} , \quad (i=1,2,\ldots, m \, ; \, j=1,2,\dots q) \label {2} \end{equation}$$
przy czym liczba wierszy pierwszej macierzy musi być równa liczbie kolumn drugiej macierzy n=q.
Przy mnożeniu macierzy prostokątnych należy zachować kolejność mnożenia , czyli w ogólności $[A] \cdot[B] \neq [B]\cdot [A]$.
Iloczynem prostym (tensorowym, Kronekera) $[C]=[A]\otimes [B]$nazywamy macierz o rozmiarze ( (mp)x(nq)) z elementami
$$ \begin{equation} c_{ij}= a_{ik} \cdot [B] \label {3} \end{equation}$$
Jeśli istnieją zwykłe iloczyny $[A]\cdot[C]$ oraz $[B]\cdot [D]$, to zachodzi
$$ \begin{equation} ([A]\otimes[B] \cdot ([C] \otimes ]D]) = [A]\cdot]C] \otimes [B]\cdot [D] \label {4} \end{equation}$$
Wyznacznik macierzy $det [A] =|A|$ został zdefiniowany w związku z rozwiązywaniem układów równań liniowych oraz analizą własności macierzy, w szczególności badaniem jej punktów osobliwych, co na przykład w teorii katastrof i stateczności oznacza punkt niestateczny układu.
Kwadratowa (n=m) macierz [A] nazywa się osobliwą jeżeli $|A| =0$
Wyznacznik iloczynu macierzy ma następujące własności:
$$ \begin{equation} |AB| =|A| \cdot |B| , \quad |A \otimes B| =A^{r1} \cdot B^{r2} \label {5} \end{equation}$$
gdzie: r1, r2 rozmiar macierzy [A] i [B] odpowiednio
Macierz transponowana $[A]^T$ powstaje poprzez przestawienie macierzy i kolumn macierzy $[A]$
$$ \begin{equation} [a_{ij}]^T_{m\times n} = [a_{ji}]_{n \times m} \label {6} \end{equation}$$
Jeśli dla kwadratowej macierzy $[A]=[A]^T$, to ta macierz jest symetryczna. Jeśli $[A]= – [A]^T$, to macierz jest skośnosymetryczna (antysymetryczna).
Macierz sprzężona (stowarzyszona, sprzężona hermitowsko) $[A]^*$ jest uogólnieniem macierzy transponowanej na przypadek macierzy z elementami w dziedzinie liczb zespolonych
$$ \begin{equation} [A]^* = [a_{ij}]^*_{m\times n} = [ \overline a_{ji}]_{n \times m} \label {7} \end{equation}$$
gdzie liczbę sprzężoną z liczbą zespoloną $a=x + i \cdot z$ (i-jednostka urojona) oznaczono przez $ \overline a = x – i \cdot z$. Jeśli dla kwadratowej macierzy $[A]= [A]^*$ , to macierz jest hermitowska (samosprzężona), a przy $[A]=-[A]^* $ jest skośnohermitowska.
Ślad macierzy jest to suma elementów diagonalnych
$$ \begin{equation} tr[A] = \sum \limits_{i=1}^n a_{ii} \label {8} \end{equation}$$
Macierz odwrotna $[A]^{-1}$ odgrywa ważną rolę w algebrze macierzy i może być zdefiniowana jako
$$ \begin{equation} [A]^{-1} \cdot [A] =1 \label {9} \end{equation}$$
Macierz odwrotna istnieje tylko dla macierzy nieosobliwej.
Jeśli istnieje $[A]^{-1}$ i $[B]^{-1}$ , to zachodzi:
$$ \begin{equation} (AB)^{-1}= [B]^{-1} [A]^{-1} , \quad ( A \otimes B)^{-1} = [A]^{-1} \otimes [B]^{-1} \label {10} \end{equation}$$
$$ \begin{equation} ([A]^{-1})^T=([A]^{T})^{-1} , \quad ([A]^{-1})^*=([A]^{*})^{T}\label {11} \end{equation}$$
$$ \begin{equation} [A]^{-1})^{-1} =[A] \label {12} \end{equation}$$
$$ \begin{equation} |[A]^{-1}| =\cfrac{1}{|A|} \label {13} \end{equation}$$
$$ \begin{equation} diag [d_1, \ldots, d_r]^{-1} = diag [\cfrac{1}{d_1}, \dots , \cfrac{1}{d_r}] \label {14} \end{equation}$$
Jeśli dla kwadratowej macierzy $[A]$ zachodzi $[A]^T [A]=[A] [A]^T$ , czyli $[A]^T=A^{-1}$, to macierz nazywa się ortogonalną, a jeśli $[A]^* [A]=[A] [A]^*$, czyli $[A]^*=[A]$, to macierz nazywa się unitarną.
Rozwiązywanie równań macierzowych
Poniżej w tekście artykułu małymi literami w nawiasach (np. [x] i [b]) oznaczane są wektory.
Podczas rozwiązywania równań macierzowych stosuje się technikę mnożenia stron równania prawostronnie lub lewostronnie.
Każde z równań liniowych
$$ \begin{equation} [A] [x]=[b] \quad \text {oraz } [x] [A]=b \label {15} \end{equation}$$
gdzie:
$[x]$ – wektor niewiadomych
$[A]$ – macierz nieosobliwa ( $|A| \neq 0$),
$[b]$ – wektor wyrazów wolnych
ma jedno i tylko jedno rozwiązanie
$$ \begin{equation} [x]=[A]^{-1} [b] \quad \text {oraz } [x] = [b] [A]^{-1} \quad \text {odpowiednio} \label {16} \end{equation}$$
przy czym (porządek mnożenia musi być zachowany.
Wybrane działania nad podmacierzami (blokami)
Rozważmy kwadratową macierz
$$ \begin{equation} [A]= \left[ \begin{array}{cc}
[A]_{11} & [A]_{12} \\
[A]_{24} & [A]_{25}
\end{array} \right ] _{(n \times n) } \label {17} \end{equation}$$
Macierz odwrotną można obliczyć w następujący sposób:
$$ \begin{equation} [A]^{-1}= \left[ \begin{array}{cc}
[A]_{11}^{-1}+ [A]_{11}^{-1} [A]_{12} [B]^{-1} [A]_{22} [A]_{11}^{-1} & – [A]_{11}^{-1}[A]_{12} [B]^{-1} \\
-[B]^{-1} [A]_{22} [A]_{11}^{-1} & [B]^{-1}
\end{array} \right ] _{(n \times n) } \label {18} \end{equation}$$
gdzie: $[B]_{(n/2 \times n/2)} = [A]_{23} – [A]_{22} A_{11}^{-1} [A]_{12}$
Użyteczną tożsamością macierzową jest
$$ \begin{equation} \left[ [A]_{11} -[A]_{12} [A]_{23}^{-1} [A]_{22} \right]^{-1} =[A]_{11}^{-1}+[A]_{11}^{-1}[A]_{12} [[A]_{23} -[A]_{22} [A]_{11}^{-1}[A]_{12}]^{-1} [A]_{22} [A]_{11}^{-1}\label {19} \end{equation}$$
Więcej o tożsamości ( $\ref{19}$) w pracy [7].
Ważną tożsamością „wyznacznikową” jest:
$$ \begin{equation} |A| =| [A]_{11}- [A]_{12} [A]_{23}^{-1} [A]_{22}] | \cdot | [A]_{23}| \label {20} \end{equation}$$
oraz
$$ \begin{equation} tr [A] = tr [A]_{11}+tr [A]_{23}\label {21} \end{equation}$$
Przekształcenia macierzowe w teorii niezawodności
W teorii niezawodności, występują przekształcenia macierzowe, które są przypadkami szczególnymi ogólnych typów przekształceń macierzowych, zestawionych w tab.1. W tabeli tej zestawiono zasadnicze własności przekształceń macierzowych, rozpatrując liniowe przekształcenie wektora x w wektor y poprzez macierz [A] i nowej przestrzeni z wektora x’ w y’ poprzez macierz transpozycji [T].
Tab. 1. Przekształcenia macierzowe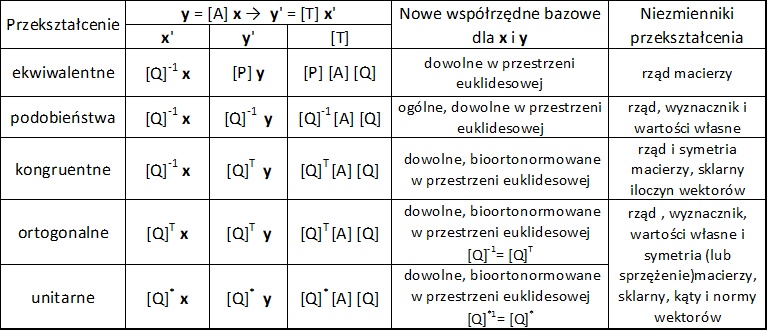
Najogólniejszym przekształceniem jest przekształcenie ekwiwalentne , gdzie [P] i [Q] są nieosobliwymi macierzami kwadratowymi. Przy [P]=[Q]-1mamy przekształcenie podobieństwa, a przy [P]=[Q]T– przekształcenie kongruentne, a jeśli przekształcenie spełnia jednocześnie warunki przekształcenia podobieństwa i kongruentności, to nazywa się przekształceniem ortogonalnym (lub unitarnym). Najważniejsze znaczenie w teorii niezawodności ma właśnie przekształcenie ortogonalne (lub unitarne), dla którego macierz transpozycji wynosi
$$ \begin{equation} [T]= [Q]^{-1} [A] [Q] = [Q]^T [A] [Q] , \quad \text {lub } [T]= [Q]^* [A] [Q] \label {22} \end{equation}$$
Macierz dla której
$$ \begin{equation} [Q]= ([Q]^{-1})^T , \quad \text {lub } [Q]= ([Q]^{-1} )^* \label {23} \end{equation}$$
nazywa się macierzą ortogonalną (lub samosprzężoną).
Różniczkowanie macierzy
Opracowano na podstawie pracy [8].
Elementami macierzy mogą być nie tylko liczby, ale również funkcje dowolnego argumentu (skalaru, wektora lub macierzy). Różniczkowanie i całkowanie takich macierzy sprowadza się do zasad analogicznych do zwykłych reguł z jedną różnicą: Ponieważ iloczyn macierzy w ogólnym przypadku nie jest przemienny, więc należy zwracać uwagę na zachowanie kolejności składania czynników.
Zachodzą dwie podstawowe zależności
$$ \begin{equation} \cfrac{\partial}{\partial t} ( [A] +[B]) = \cfrac{\partial [A]}{\partial t} + \cfrac{\partial [B]}{\partial t}\label {24} \end{equation}$$
$$ \begin{equation} \cfrac{\partial}{\partial t} ( [A] [B]) = \cfrac{\partial [A]}{\partial t} [B] + [A] \cfrac{\partial [B]}{\partial t} \label {25} \end{equation}$$
Jeśli macierz $[A](t)$ jest różniczkowalna i posiada macierz odwrotną $[A]^{-1} (t)$, to
$$ \begin{equation} \cfrac{ \partial [A]^{-1}} {\partial t } = -[A]^{-1} \cfrac{ \partial [A]}{\partial t} [A]^{-1} \label {26} \end{equation}$$
$$ \begin{equation} \cfrac{ \partial |A| } {\partial t } = |A| \cdot tr \left ( [A]^{-1} \cfrac{\partial [A]}{\partial t }\right ) \label {27} \end{equation}$$
Rozwinięcie funkcji wektorowej w szereg Taylora
Rozważmy zmienną wektorową
$[Z]=[Z_1,Z_2, \ldots, Z_m]_{1 \times m} $
będącą funkcją wektorową F([X]) wektora
$[X]=[X_1,X_2, \ldots, X_n]_{1 \times n} $
W zapisie klasycznym funkcję na j-tą współrzędną wektora [Z] można zapisać w postaci $Z_j = F_j([X])$. Rozwinięcie w szereg Taylora tej funkcji wokół punktu $[X]_0$ można zapisać w postaci:
$$ \begin{equation} Z_j=F_j([X]) =F_j ([X]_0) +\cfrac{1}{1!} \sum \limits_{i=1}^n \cfrac{\partial F_j ([X])}{\partial X_i} \Big |_{( [X]=[X]_0)} \cdot \left( X_i-X_{0i} \right) + \\ \cfrac{1}{2!} \sum \limits_{i=1}^n \sum \limits_{k=1}^n \cfrac{ {\partial}^2 F_j ([X])}{\partial X_i \partial X_k}\Big |_{( [X]=[X]_0)} \cdot \left( X_i-X_{0i} \right )\cdot \left( X_k-X_{ok} \right) + R\label {28} \end{equation}$$
Równanie ($\ref{28}$) jest wielomianem aproksymacyjnym, w którym reszta R zawiera składniki rzędu wyższego niż drugi. Zapis ($\ref{28}$) w postaci jawnej podaje człon stały, liniowy i drugiego rzędu paraboli stycznej do funkcji oryginalnej w punkcie.
W zapisie macierzowym rozwinięcie ($\ref{28}$) przy pominięciu reszty R (aproksymację II rzędu) można przedstawić w postaci:
$$ \begin{equation} [Z] \approx F([X]_0) + \partial F([X]_0) \cdot \left ([X]- [X]_0 \right ) + 1/2 \left([X]=-[X]_0 \right)^T \partial^2 F([X]_0) \left(]X]-[X]_0 \right) \label {29} \end{equation}$$
gdzie:
$F([X]_0)$ – stały wektor kolumnowy zawierający wartości funkcji w punkcie $[X]_0]$,
$$ \begin{equation} \partial F([X]_0) = \left[ \begin{array}{cccc}
\cfrac{\partial F_1}{\partial X_1} & \cfrac{\partial F_1}{\partial X_2} & \cdots & \cfrac{\partial F_1}{\partial X_n} \\
\vdots & \vdots & \vdots & \vdots & \\
\cfrac{\partial F_m}{\partial X_1} & \cfrac{\partial F_m}{\partial X_2} & \cdots & \cfrac{\partial F_m}{\partial X_n} \\
\end{array} \right ] _{[X]=[X]_0} \label {30} \end{equation}$$
– macierz wrażliwości pierwszego rzędu, o wymiarze $m \times n$, zawierająca wartości macierzy Jacobiego w punkcie , którą zwykle nazywa się jakobianem.
$\partial^2 F([X]_0)$ – trójwymiarowa macierz wrażliwości drugiego rzędu o wymiarze $m \times n \times n$ , której składowymi są współrzędne j-te, stanowiące macierze o wymiarze $n \times n$:
$$ \begin{equation} \partial^2 F_j([X]_0) = \left[ \begin{array}{cccc}
\cfrac{\partial^2 F_j}{\partial X_1 \partial X_1} & \cfrac{\partial^2 F_j}{\partial X_1 \partial X_2} & \cdots & \cfrac{\partial^2 F_j}{\partial X_1\partial X_n} \\
\vdots & \vdots & \vdots & \vdots & \\
\cfrac{\partial^2 F_j}{\partial X_n \partial X_1} & \cfrac{\partial^2 F_j}{\partial X_n \partial X_2} & \cdots & \cfrac{\partial^2 F_j}{\partial X_n\partial X_n} \\
\end{array} \right ] _{[X]=[X]_0} \label {31} \end{equation}$$
zawierające wartości pochodnych drugiego rzędu współrzędnej $F_j$ wektora $[F]$ podług wektora $[X]$ w punkcie $[X]_0$. Macierz tą nazywa się hesjanem.
Wybrane elementy teorii prawdopodobieństwa i statystyki
Podstawowe zmienne, funkcje losowe i ciągłe rozkłady prawdopodobieństwa
W tab.2. zestawiono podstawowe wiadomości o zmiennych i funkcjach losowych ciągłych, W tab.3. zestawiono informacje o podstawowych typach ciągłych rozkładów prawdopodobieństwa, a w tab 4 najważniejsze estymatory parametrów rozkładów prawdopodobieństwa
Tab.2. Podstawowe zmienne i funkcje losowe ciągłe

Tab.3 Wybrane rozkłady jednowymiarowych rozkładów zmiennych losowych ciągłych

Tab.4. Estymatory parametrów oraz kwantyle wybranych rozkładów prawdopodobieństwa

Charakterystyki wektorów losowych
Opracowano na podstawie pracy [4].
Rozpatrzmy wektor losowy $[X]=[X_1, \ldots, X_n] $ oraz wektor losowy $[Y]=[Y_1, \ldots, Y_m]$, których współrzędnymi są zmienne losowe $X_i \quad (i=1,\ldots,n)$ i $Y_j \quad (j=1,\ldots, m)$ odpowiednio .
Wartość oczekiwana lub moment pierwszego rzędu wektora losowego $[X]$ oraz $[Y]$ są wektorami wartości oczekiwanych ich współrzędnych:
$$ \begin{equation} m_X= E[X] = [EX_1, \ldots EX_n] ; \quad m_Y= E[Y] = [EY_1, \ldots EY_m] \label {32} \end{equation}$$
Momentem drugiego rzędu losowych wektorów ]X] i [Y] nazywa się macierz (w ogólności prostokątną) wartości oczekiwanych iloczynu ich współrzędnych:
$$ \begin{equation} [ \Gamma_{XY} ] = E[XY^*] = E[(X_i \cdot \overline Y_j)]_{m \times n} = [g_{ij}]_{m \times n} \label {33} \end{equation}$$
Macierzą kowariancji nazywamy momenty drugiego rzędu centrowanych wektorów $[X]^0=[X-m_X]$ oraz $[Y]^0=[Y-m_Y]$
$$ \begin{equation} [ C_{XY} ] = E[X^0Y^{0*}] = E[(X_i-m_i) \cdot ( \overline Y_j -\overline m_{yj}) = [Cov(X_i X_j)]_{m \times n} =[c_{ij}]_{m \times n} \label {34} \end{equation}$$
Nadkreśleniem oznaczono sprzężoną wartość zespoloną, a gwiazdką (*) macierz sprzężoną, która dla macierzy rzeczywistych staje się macierzą transponowaną. Momenty drugiego rzędu, macierz kowariancji oraz wartości oczekiwane są związane zależnością:
$$ \begin{equation} [ \Gamma_{XY} ] = [C_{XY}] +m_X {m_Y}^* \label {35} \end{equation}$$
Wektory $[X]$ i $[Y]$ są skorelowane, jeśli $C_{XY}\neq 0$ i nieskorelowane, jeśli $C_{XY}=0$.
Elementy diagonalne macierzy kowariancji współrzędnych wektora [X] nazywamy wariancją wektora losowego
$$ \begin{equation} Var [X] = [CovX_i X_j] \label {36} \end{equation}$$
Współrzędne wektora [X] są nieskorelowane wówczas, gdy macierz kowariancji jest diagonalna $C_{XX}=diag [VarX_1, \ldots, Var X_n]$.
Aby wielkości losowe były nieskorelowane wystarcza, by ich łączny rozkład był symetryczny względem dowolnej prostej, równoległej do osi współrzędnych.
Macierz korelacji jest zdefiniowana jako:
$$ \begin{equation} R_{XY}= \left[ \begin{array}{cccc}
r_{11} & r_{12} & \cdots & r_{1n} \\
\vdots& \vdots& \vdots& \vdots& \\
r_{m1} & r_{n2} & \cdots & r_{mn}
\end{array} \right ] _{(n \times m) }\label {37} \end{equation}$$
gdzie
$$ \begin{equation} r_{ij}= \cfrac{ [Cov(X_i X_j)]}{\sqrt{ Var X_i Var X_j}} \label {38} \end{equation}$$
Najważniejszymi własnościami momentów drugiego są:
- macierz drugich momentów wektora [X] z samym sobą jest hermitowska (jeśli jest rzeczywista to jest symetryczna)
$$ \begin{equation} [R_{XX}]=[R_{XX}]^* \label {39} \end{equation}$$
i dodatnio określona, czyli dla każdego wektora $[A] \neq 0$ , zachodzi
$$ \begin{equation} [A] [R_{XX}] [A]^* > 0\label {40} \end{equation}$$
Z drugiej strony każda macierz posiadająca te dwie własności może być macierzą kowariancji, a więc i macierzą drugich momentów wektora losowego.
Macierz drugich momentów oraz macierz kowariancji wektora [X] z samym sobą jest dodatnio określona. Z dodatniej określoności macierzy [R_{XX}] lub [ C_{XX}] wynika, że ich wyznacznik jest nieujemny i równy zero wtedy i tylko wtedy, gdy współrzędne wektora [X] są liniowo zależne.
2. Przy zmianie porządku wektorów losowych ich drugi moment i macierz kowariancji zostanie przekształcona w hermitowsko sprzężone macierze
$$ \begin{equation} [R_{YX}] = [R_{XY}]^* \label {41} \end{equation}$$
Przy liniowym przekształceniu losowego wektor [x] w losowy wektor [y]
$$ \begin{equation} [y] = [A] [x][ +[b] \label {42} \end{equation}$$
gdzie [A], [b] – nielosowa macierz przekształcenia i wektor przesunięcia [b]
wartość oczekiwana jest więc liniowym operatorem, a przekształcenie macierzy kowariancji jest przekształceniem ortogonalnym (lub sprzężonym):
$$ \begin{equation} [m_y] = [A] [m_x] + [b] \label {43} \end{equation}$$
$$ \begin{equation} [C_{yy}]= [A] [C_{xx}] [A]^* \label {44} \end{equation}$$
Wyrażenie (\ref{44}) można uogólnić na przypadek niezależnego liniowego przekształcenia wektora [x] oraz wektora [y]:
$$ \begin{equation} Cov ( [A] [x]+[b], [D] [y] +[e])= [A][C_{xy}] [D]^* \label {45} \end{equation}$$
Transformacja dowolnego wektora losowego na wektor o nieskorelowanych współrzędnych
W zadaniach niezawodności konstrukcji, wygodnie operować wektorami losowymi o nieskorelowanych współrzędnych. Zadanie transformacji dowolnego losowego wektora [x] na wektor [y] o nieskorelowanych współrzędnych, nazywane często dekorelacją wektora losowego. Wektor o nieskorelowanych współrzędnych w ogólności pozostaje wektorem o współrzędnych zależnych losowo, a jest wektorem o współrzędnych niezależnych losowo w przypadku szczególnych łącznych rozkładów prawdopodobieństwa, w tym rozkładu normalnego (p. artykuł Dekoleracja wektora losowego).
Zadanie to sprowadza się sprowadza się do liniowego przekształcenia nazywanego kanonicznym rozkładem wektora losowego:
$$ \begin{equation} [x]= [T] [y] +[m_x] \label {46} \end{equation}$$
z macierzą przekształcenia [T], którą wyznacza się w sposób analogiczny do poszukiwania wektorów własnych macierzy w sposób pokazany niżej. Dążymy mianowicie do takiego przekształcenia macierzy kowariancji wektora $[x]$, by sprowadzić ją do macierzy diagonalnej z odwróconej zależności ($\ref{44}$)
$$ \begin{equation} [C_{xx}]= [T] [C_{yy}] [T]^* \label {47} \end{equation}$$
Rozkład kanoniczny wektora losowego można dokonać nieskończenie wieloma sposobami, z których w praktyce stosowane są [4]:
- poszukiwanie wartości własnych macierzy kowariancji – w tym przypadku macierz przekształcenia jest złożona z wektorów własnych tej macierzy. Ten sposób stosuje się chętnie, ponieważ pakiety standardowych procedur numerycznych zawierają procedury rozwiązywania problemu wartości własnych.
- inne rozkłady bez wymogu normalizacji przekształcenia, które co prawda nie są standardowe, lecz prowadzą do istotnie mniej kosztownych algorytmów.
Poniżej podajemy algorytm kanonicznego rozkładu wektora losowego [x] z macierzą kowariancji $[C_{xx}]_{n \times n} = [c_{ij}], \quad (i, j = 1,\ldots, n)$, w wyniku którego otrzymujemy wektor $[y]$ z nieskorelowanymi wyrazami, czyli $[C_{yy}]_{n \times n} = diag [d_k], \quad (k = 1,\ldots, n) $
przy stosowaniu którego rozmiar obliczeń jest dziesiątki, a w niektórych przypadkach setki razy mniejszy od rozwiązywania zagadnienia własnego, choć rozwiązanie nie jest unormowane.
Macierz kowariancji wektora $[y]$ oraz macierz przekształcenia $[T]=[t_{kj}] $ można wyznaczyć z algorytmu opisanego zależnościami:
$$\begin{equation} d_k = \begin{cases}
c_{11}, & \text { dla } \, ( k=1 ) \\
c_{kk} – \sum \limits _{i=1}^{k-1} d_i \cdot |t_{ik}|^2, & \text { dla } (k=2, \ldots, n) \\
\end{cases} \label {48} \end{equation}$$
$$\begin{equation} t_{kj} = \begin{cases}
c_{j1}/d_1,& \text { dla } (k=1), \quad (j=1,\dots, n) \\
\cfrac{1}{d_k}\cdot \left( c_{jk} – \sum \limits _{i=1}^{k-1} d_i \cdot t_{ij} \cdot \overline t_{ik} \right),& \text {dla } (k=2, \ldots n), \quad (j=k+1, \ldots, n)\\
\end{cases} \label {49} \end{equation}$$
Jeśli $d_k=0$, to przyjmujemy $t_{k1}= \ldots, t_{kn}=0$
Można wykazać ( [4]), że macierz przekształcenia [T] jest macierzą górną trójkątną z jedynkami na głównej przekątnej, to znaczy jest typu:
$$ \begin{equation} [T]=[t_{kj}]_{(n \times n)} = \left[ \begin{array}{ccccc}
1 & t_{12} & t_{13}& \cdots & t_{1n} \\
0 & 1 & t_{24}& \cdots & t_{2n} \\
0 & 0 & 1& \cdots & t_{3n} \\
\vdots& \vdots& \vdots& \vdots& \vdots\\
0 & 0 & 0&\cdots & 1
\end{array} \right ] \label {50} \end{equation}$$
Przykład 1. [Dekorelacja wektora losowego]
Wykonać dekorelację (rozkład kanoniczny) wektora $[x]$ z wartością oczekiwaną ($\ref{32}$) $m_x=0$ i wektorem wariancji ($\ref{36}$) $V_x= [400, 25,100, 9] $, oraz:
macierzą korelacji($\ref{37}$)
$$ \begin{equation} [R_{xx}]= \left[ \begin{array}{cccc}
1 & 0,5 & 0,1 & 0,2 \\
& 1 & 0,4 & 0,2 \\
SYM & & 1 & 0,3 \\
& & & 1 \\
\end{array} \right ] \label {51} \end{equation}$$
więc na podstawie ($\ref{38}$) z macierzą kowariancji ($\ref{34}$)
$$ \begin{equation} [C_{xx}]=[c_{ij}] \left[ \begin{array}{cccc}
400 & 50 & 20 & 12 \\
50 & 25 & 20 & 13 \\
20& 20 & 100 & 9 \\
12 & 13 & 9 & 9 \\
\end{array} \right ] \label {52} \end{equation}$$
Wykonując działania przypisane formułami ($\ref{48}$) i ($\ref{52}$) otrzymujemy kolejno:
$d_1= c_{11}= 400$,
$t_{11}= c_{11}/d_1= 400/400=1$,
$t_{12}= c{22}/d_1 = 50/400 = 0,1250$
$t_{13}=c_{32}/d_1= 20/400= 0,0500$
$t_{14}=c_{42}/d_1=12/400 =0,0300$
$d_2=c_{23}-(d_1 \cdot |t_{12}|^2 = 25 – ( 400 \cdot |0,125|^2) = 18,75$
$t_{22} = \cfrac{1}{d_2} \cdot [ c_{12} – (d_1 \cdot t_{11} \cdot t_{12})] = \cfrac{1}{18,75} \cdot [ 50 – (400 \cdot 1 \cdot 0,1250)]= 0$
$t_{23} = \cfrac{1}{d_2} \cdot [ c_{23} – (d_1 \cdot t_{12} \cdot t_{12})] = \cfrac{1}{18,75} \cdot [ 25 – (400 \cdot 0,125 \cdot 0,125)]= 1$
$t_{24} = \cfrac{1}{d_2} \cdot [ c_{33} – (d_1 \cdot t_{13} \cdot t_{12})] = \cfrac{1}{18,75} \cdot [ 20 – (400 \cdot 0,05 \cdot 0,125)]= 0,93333$
$t_{25} = \cfrac{1}{d_2} \cdot [ c_{43} – (d_1 \cdot t_{14} \cdot t_{12})] = \cfrac{1}{18,75} \cdot [ 13 – (400 \cdot 0,03 \cdot 0,125)]= 0,61333$
$d_3=c_{34}-(d_1 \cdot |t_{13}|^2 + d_2 \cdot |t_{24}|^2) = 100 -( 400 \cdot |0,05|^2+ 18,75 \cdot |0,93333|^2) = 82,6667$
$t_{32} = \cfrac{1}{d_3} \cdot [ c_{13} – (d_1 \cdot t_{11} \cdot t_{13} + d_2 \cdot t_{22} \cdot t_{24}] =\\
= \cfrac{1}{82,667} \cdot [ 20 – (400 \cdot 1 \cdot 0,05+18,75 \cdot 0 \cdot 0,9333) ]= 0$
$t_{33} = \cfrac{1}{d_3} \cdot [ c_{24} – (d_1 \cdot t_{12} \cdot t_{13} + d_2\cdot t_{23} \cdot t_{24}] =\\
= \cfrac{1}{82,667} \cdot [ 20 – (400 \cdot 0,125 \cdot 0,05 + 18,75 \cdot 1 \cdot 0,9333) ]= 0$
$t_{34} = \cfrac{1}{d_3} \cdot [ c_{34} – (d_1 \cdot t_{13} \cdot t_{13} + d_2\cdot t_{24} \cdot t_{24}] =\\
= \cfrac{1}{82,667} \cdot [ 100 – ( 400 \cdot 0,05 \cdot 0,05 + 18,75 \cdot 0,9333 \cdot 0,9333) ]= 1$
$t_{35} = \cfrac{1}{d_3} \cdot [ c_{44} – (d_1 \cdot t_{14} \cdot t_{13} + d_2\cdot t_{25} \cdot t_{24}] =\\
= \cfrac{1}{82,667} \cdot [ 9 – (400 \cdot 0,03 \cdot 0,05+ 18,75 \cdot 0,61333 \cdot 0,9333) ]= -0,02823$
$d_4=c_{45}-(d_1 \cdot |t_{14}|^2 + d_2 \cdot |t_{25}|^2 +d_3 \cdot |t_{35}|^2 ) =\\
= 9 – ( 400 \cdot |0,03|^2+ 18,75 \cdot |0,61333|^2 +82,667 \cdot |-0,02823|^2) = 1,52081$
$t_{42} = \cfrac{1}{d_4} \cdot [ c_{14} – (d_1 \cdot t_{11} \cdot t_{14} + d_2 \cdot t_{22} \cdot t_{25}+d_3\cdot t_{32} \cdot t_{35})] =\\
= \cfrac {1}{1,52081} \cdot [ 12 – (400 \cdot 1 \cdot 0,03+18,75 \cdot 0 \cdot 0,9333 +82,667 \cdot 0 \cdot (-0,02823)) ]= 0$
$t_{43} = \cfrac{1}{d_4} \cdot [ c_{25} – (d_1 \cdot t_{12} \cdot t_{14} + d_2 \cdot t_{23} \cdot t_{25}+d_3 \cdot t_{33} \cdot t_{35})] =\\
= \cfrac {1}{1,52081} \cdot [ 13 – (400 \cdot 0,125 \cdot 0,03 + 18,75 \cdot 1 \cdot 0,61333 + 82,667 \cdot 0 \cdot (-0,02823) ) ]= 0 $
$t_{44} = \cfrac{1}{d_4} \cdot [ c_{35} – (d_1 \cdot t_{13} \cdot t_{14} + d_2\cdot t_{24} \cdot t_{25}+d_3 \cdot t_{34} \cdot t_{35}) ] =\\
= \cfrac {1}{1,52081} \cdot [ 9 – ( 400 \cdot 0,05 \cdot 0,03 + 18,75 \cdot 0,93333 \cdot 0,61333 + 82,667 \cdot 1 \cdot (-0,02823) ]= 0$
$t_{45} = \cfrac{1}{d_4} \cdot [ c_{45} – (d_1 \cdot t_{14} \cdot t_{14} + d_2\cdot t_{25} \cdot t_{25}+d_3\cdot t_{35} \cdot t_{35})] =\\
= \cfrac {1}{1,52081} \cdot [ 9 – (400 \cdot 0,03^2 + 18,75 \cdot 0,61333^2 +82,6667 \cdot (-0,02823)^2) ]= 1$
i w rezultacie
$$ \begin{equation} [T]= \left[ \begin{array}{cccc}
1 & 0,1250 & 0,0500 & 0,0300\\
0 & 1 & 0,9333 & 0,61333 \\
0 & 0 & 1 & – 0,02822 \\
0 & 0 & 0 & 1 \\
\end{array} \right ] \label {53} \end{equation}$$
$$ \begin{equation} [C_{yy}]= \left[ \begin{array}{cccc}
400 & 0 & 0 & 0\\
0 & 18,75 & 0 & 0 \\
0 & 0 & 82,667 & 0 \\
0 & 0 & 0 & 1,52081 \\
\end{array} \right ] \label {54} \end{equation}$$
Funkcje wielkości losowych
Ogólną zasadę znajdowania rozkładu funkcji $Y=\varphi (X)$ losowej wielkości [X] zilustrowano na rys. 1 na przykładzie jednowymiarowych wielkości losowych $X$ i $Y$ , które przyjmują wartości $x$ i $y$.

Rys.1. Odwzorowanie funkcji losowej
. Z ilustracji wynika wprost, że
$$ \begin{equation} Pr (Y \in B) =Pr(X \in \{ A=\varphi^{-1} (B) \} \label {55} \end{equation}$$
Stąd
$$ \begin{equation} Pr (Y \in B) =\int _B f_Y(y) dy = Pr(X \in \ A) = \int _A f_X (x) dx \label {56} \end{equation}$$
Po zamianie $ x=\varphi^{-1}(y)$ oraz $ A \to B$, otrzymujemy
$$ \begin{equation} \int \limits_A f_X (x) dx = \int \limits_A f_X( \varphi^{-1}(y)) J(y) dy \label {57} \end{equation}$$
gdzie $J(y)$ jest jakobianem współrzędnych wektora $[x= {\varphi(y)]}^{-1}$ dany wzorem
$$ \begin{equation} [J(y)]= \left[ \begin{array}{cccc}
\cfrac{\partial { \varphi_1}^{-1}} {\partial y_1}& \cfrac{\partial { \varphi_2}^{-1}} {\partial y_1} & \cdots & \cfrac{\partial { \varphi_n}^{-1}} {\partial y_1} \\
\vdots& \vdots& \vdots& \vdots& \\
\cfrac{\partial { \varphi_1}^{-1}} {\partial y_n}& \cfrac{\partial { \varphi_2}^{-1}} {\partial y_n} & \cdots & \cfrac{\partial { \varphi_n}^{-1}} {\partial y_n} \\
\end{array} \right ] _{(n \times n) }\label {58} \end{equation}$$.
W zależności od tego jak wybierzemy obszar „B” , otrzymuje się różne sposoby wyznaczania rozkłady zmiennej $Y$ .
W szczególności , jeśli $B=\{ Y<y \}$, to $A=\{ x: \varphi (x) <y \}$ i poszukujemy dystrybuantę zmiennej $Y=\varphi(X)$.
W celu określenia dystrybuanty zmiennej $Y=\varphi(X)$ koniecznym i wystarczającym warunkiem jest, aby funkcja $\varphi (x)$ była spełniała tylko jeden warunek: dla dowolnego $y$ powinna być możliwe wyznaczenia prawdopodobieństwa przyjmowania przez nią wartości z przedziału $A=\{ x: \varphi (x) <y$ Takie funkcje nazywają się „mierzalnymi”, a spotykane w praktyce funkcje spełniają ten warunek, a dodatkowo w większości są funkcjami ciągłymi i często różniczkowalnymi.
Dla znanej funkcji gęstości rozkładu prawdopodobieństwa $f_1(x)$ losowej zmiennej $X$ z zasady $\ref{57}$}) dystrybuantę $F_2(y)$ zmiennej losowej $Y=\varphi(X)$ można wyznaczyć z formuły
$$ \begin{equation}F_2(y) = \int \limits_A f_1(x) = \int \limits_{\varphi(x) <y} f_1(x) dx\label {59} \end{equation}$$
Powyższa formuła jest prawdziwa zarówno dla skalarnych jak i wektorowych zmiennych $X$ i $Y$
Przykład 2. [Dystrybuanta ilorazu zmiennych losowych ]
Przykład 4.9 z pracy [4]
Znaleźć rozkład prawdopodobieństwa ilorazu $Z= X/Y$ zmiennych losowych $X$ i $Y$ o łącznym rozkładzie prawdopodobieństwa $f_1(x,y)$
Uwzględniając, że $y/x <z$ przy $y<zx$ , jeśli $x>0$ , i przy $y> zx$, jeśłi $x<0$ z formuły ($\ref{59}$) mamy
$$ \begin{equation} F_2(y) = \iint \limits_{y/x<z} f_1(x,y) dx dy= \int \limits_{-\infty} ^0 dx \int \limits_{zx}^\infty f_1(x,y) dy +\int \limits_{0} ^\infty dx \int \limits_{-\infty}^{zx} f_1(x, y) dy\label {60} \end{equation}$$
Różniczkując tę formułę po $z$, znajdujemy funkcję gęstość rozkładu zmiennej $Z$:
$$ \begin{equation} f_2(z) = \iint \limits_{-\infty}^\infty |x| f_1(x, zx) dx \label {61} \end{equation}$$
W szczególności w przypadku kołowej symetrii rozkładu argumentów $f_1(x,y) = p \cdot (x^2+y^2)$ formuła ($\ref{61}$) przyjmie postać
$$ \begin{equation} f_2(z) = 2 \cdot \iint \limits_0^\infty xp (x^2 (1+z^2)) dx \label {62} \end{equation}$$
Po dokonaniu zamiany zmiennych $u=\sqrt{1 =z^2}$ ($\ref{62}$)możemy zapisać w postaci
$$ \begin{equation} f_2(z) =\cfrac{2}{1+z^2} \int \limits_0^\infty up (u^2) du\label {63} \end{equation}$$
Całkę ($\ref{63}$) można wyznaczyć ściśle , korzystając z warunku równości jedności całki z $f_2(z)$ po całym obszarze zdarzeń , czyli w granicach $z \in (-\infty, \infty)$ . W rezultacie uzyskujemy wynik
$$ \begin{equation} f_2(z) =\cfrac{1}{\pi \cdot (1+z^2)} \label {64} \end{equation}$$
czyli stwierdzamy, że rozkład ilorazu dwóch zmiennych losowych o dowolnym kołowosymetrycznym rozkładzie prawdopodobieństwa jest rozkładem Cauchy.
W przykładzie 3.6 [4] – str 95 oryginału wskazano, że zmienna losowa Z o rozkładzie Cauchy w ogólności nie posiada wartości oczekiwanej. Dopiero przy dodatkowym założeniu o symetrii rozkładu Cauchy wokół punktu $m_z$:
$$ \begin{equation} f(z) =\cfrac{b}{\pi \cdot (b^2+(z-m_z)^2)} \label {65} \end{equation}$$
wartość oczekiwana takiego rozkładu wynosi $m_z$, ale wariancja nadal jest nieokreślona ($Var(z)=\infty$).
W konkluzji przykładu należy stwierdzić, że dla stosunku zmiennych losowych teoretycznie nie istnieją momenty statystyczne, ale względy praktyczne sugerują, że powinno istnieć przybliżenie przystające do obserwacji świata., który jest ciągły i skończony. Teoretyczne, idealne rozkłady prawdopodobieństwa też nie istnieją. Bliższe rzeczywistości mogą być więc aproksymacje, przybliżenia. Takie aproksymacje stosunku dwóch zmiennych losowych $X$ i $Y$ normalnie rozłożonych badał m.in. Marsaglia ( 2006) [9]. Na podstawie wielu analiz numerycznych podał, że stosunek normalnych zmiennych spotykanych w praktyce sam może być traktowany jako normalnie rozłożony i dla zawsze dodatniego mianownika $Y>0$, rozkład Z, wynosi
$$\begin{equation} Pr \{ x/y <t \} \approx Pr \{ y- t\cdot x <0\} =\Phi \left( \cfrac{t\cdot m_y -m_x}{\sqrt{\sigma_x^2 – 2\cdot t \cdot c +t^2 \cdot \sigma_y^2}}\right ) \label {66} \end{equation}$$
gdzie:
$c=Cov(X,Y) = \rho \cdot \sigma_x \cdot \sigma_y$,
$\sigma_*$ – odchylenie standardowe zmiennej *.
$\rho$ – współczynnik korelacji zmiennych X i Y.
Dla ustalonej chwili czasu i sytuacji projektowej w praktyce projektowej można przyjąc, że zmienna $Z$ jest dodatnia (znaki X i Y są takie same, co w rezultacie umożliwia przyjęcie dodatniości zmiennej Y . Taka sytuacja wystąpi na przykład wówczas, gdy $Z=\Lambda$ jest mnożnikiem obciążeń, w tym obciążeń krytycznych.
Pola losowe i procesy stochastyczne
Klasyfikacja pól losowych
Pole losowe jest funkcją losową indeksowaną parametrem nielosowym (najczęściej czasem). W przypadku dyskretnego zbioru indeksów pole losowe jest ciągiem zmiennych losowych.
W ogólnym przypadku pole losowe może być wektorowe (wielowymiarowe) indeksowane wektorem nielosowym (wieloma parametrami skalarnymi).
Jeśli wektor nielosowych parametrów pola losowego degeneruje się do skalara, to takie pole nazywa się procesem stochastycznym. Proces stochastyczny może być wielowymiarowy – w tym przypadku dla ustalonego parametru nielosowego generowane zmienne losowe są wektorami.
Przykład 3. [Przykłady wektorowych pól losowych]
- Wektorowe pole losowe [X(t)] parametryzowane wektorem nielosowym [t]:
$$ \begin{equation} [X[t]]=\left[ \begin{array}{c} X_1 &\\ X_2 &\\\vdots&\\ X_m & \end{array} \right ] = \left[ \begin{array}{c} \text {gestość materiału} &\\ \text {granica plastycznosci} &\\ \vdots& \\ \ldots & \end{array} \right ] \label {67} \end{equation}$$
gdzie:
$$ \begin{equation} [t]=\left[ \begin{array}{c} t_1 &\\ t_2 &\\ t_3 \vdots&\\ t_m & \end{array} \right ] = \left[ \begin{array}{c} \text {współrzędna przestrzenna x} &\\ \text {współrzędna przestrzenna y } & \\ \text {współrzędna przestrzenne z} \\ \vdots& \\ \ldots & \end{array} \right ]\label {68} \end{equation}$$
- Proces stochastyczny parametryzowany wektorem nielosowym [t] jest współrzędną pola ($\ref{67}$).
- Wektorowe pole losowe parametryzowane skalarem nielosowym jest polem ($\ref{67}$) przy ustaleniu wszystkich parametrów nielosowych z wyjątkiem (t_•}.
- Skalarny proces stochastyczny jest współrzędną pola ($\ref{67}$) zależną od parametru skalarnego $t$ .
W zależności od natury pól losowych wyróżnijmy następujące ich typy:
- pola stacjonarne (jednorodne), izotropowe i/lub ergodyczne,
- pola o przyrostach nieskorelowanych, ortogonalnych lub niezależnych,
- procesy Markowa i/lub procesy normalne (gaussowskie).
Definicje tych pól podano poniżej, po uprzednim zdefiniowaniu stosownych charakterystyk.
W dalszym ciągu w tym punkcie zajmiemy się n-wymiarowym polem wektorowym
$$ \begin{equation} [X[t]]=\left[ \begin{array}{c} X_1([t]) &\\ X_2([t]) &\\\vdots&\\ X_n([t]) & \end{array} \right ]^T \label {69} \end{equation}$$
złożonym z pól skalarnych $ X_1([t])$, $X_2([t])$, $\ldots$ , $X_n([t])$ parametryzowanych nielosowym wektorem $[t]$. Omówimy wybrane własności tego pola w szerszym sensie, to znaczy własności generowane przez momenty statystyczne pola. Ograniczymy się do teorii korelacyjnej dotyczącej trendu i kowariancji pola. Mocniejsze własności w wąskim sensie generowane przez funkcje statystycznego rozkładu pola nie będą omawiane.
Wartość oczekiwana i wariancja pola losowego
Dwa pierwsze momenty pola są zdefiniowane następująco:
- trend pola (wartość oczekiwana)
$$ \begin{equation} [M([t]]=\left[ \begin{array}{c} M_1([t]) &\\ M_2([t]) &\\\vdots&\\ M_n([t]) & \end{array} \right ]^T = \left[ \begin{array}{c} EX_1([t]) &\\ EX_2([t]) &\\\vdots&\\ EX_n([t]) & \end{array} \right ]^T\label {70} \end{equation}$$
gdzie $E$ jest operatorem wartosci oczekiwanej,
2) korelacja
$$ \begin{equation} R(t_1,t_2)= E(X(t_1) \cdot X^T(t_2) ] = \left[ \begin{array}{cccc}
R_{11} & R_{12} & \cdots & R_{1n} \\
\vdots& \vdots& \vdots& \vdots& \\
R_{n1} & R_{n2} & \cdots & R_{nn}
\end{array} \right ]^T \label {71} \end{equation}$$
lub kowariancja (korelacja centralna)
$$ \begin{equation} C(t_1,t_2) = R(t_1,t_2) – M(t_1) \cdot M^T(t_2) \label {72} \end{equation}$$
Wariancję $C_{ii}(t_1,t_2)$ tego samego procesu $X_i(t)$ (element diagonalny macierzy ($\ref{72}$) nazywa się autokowariancją.
Wariancję $C){ij}(t_1,t_2)$ procesów $X_i(t)$ oraz $X_j(t)$ (element pozadiagonalny macierzy ($\ref{72}$) nazywa się interkowariancją.
Dla ustalonej chwili $[t]=[t_1]=[t_2]$ macierz ($\ref{72}$) staje się macierzą korelacji wielowymiarowego wektora losowego z diagonalnymi elementami równymi wariancji zmiennej $X_i$
$$ \begin{equation} \sigma_i^2 = Var(X_i)= C_{ii}(t_1, t_2) = R_{ii} (t_1,t_2) -m_i^2 (t) \label {73} \end{equation}$$
Procesy stochastyczne
W podręczniku przyjmuje się inżynierska definicję procesu stochastycznego jako rodzinę zmiennych losowych indeksowaną za pomocą pewnego nielosowego parametru $t$. Jeśli parametr t jest związany z czasem to mamy do czynienia z właściwym procesem stochastycznym, czyli rozciągniętym w czasie. W inżynierii procesami stochastycznymi nazywamy procesu losowe indeksowane również innymi parametrami (np. bieżącą współrzędną po długości pręta) i do takich procesów stosujemy te same narzędzia matematyczne.
Jeśli rozważamy dyskretny proces $X(t)$ względem parametru $t$, to znaczy indeksowany liczbami porządkowymi $( t=1, \dots, n)$, to zadanie sprowadza się do badania n-wymiarowego wektora losowego $[X_1, X_2, \ldots , X_n]$. W takim podejściu w celu kompletnego zdefiniowania procesu stochastycznego wystarczy podać łączna funkcję gęstości rozkładu prawdopodobieństwa
$$ \begin{equation} p(x_1, x_2,\ldots, x_n) \label {74} \end{equation}$$Literatura
- Bellman R., (1960), Introduction to Matrix Analysis, Mc Graw-Hill, New Yor), ((Bodewig H., (1956), Matrix Calculus, Wiley-Interscience, New York
- Franklin J., (1968), Matrix Theory, Prentice-Hall, New York
- Schweppe F.C., (1978), Układy dynamiczne w warunkach losowych, Wydawnictwo Naukowo-Techniczne, Warszawa
- Pugatchev, V. S. (1984), Probability theory and mathematical statistics for engineers (1st Ed.), Pergamon Press [ tłum. oryg. Teorija verojatnostej i matematicheskaja statisitika, Izadatelstvo Nauka, Moskva, 1979
- Weber H. J. , Arfken G.B., (2003), Essential Mathematical Methods for Physicists, Academic Press, an imprint of an Elsevier Science
- O’Neil P., (2012, 7-th Ed.), Advanced Engineering Mathematics, www.librosysolucionarios.net
- Bodewig H., (1956), Matrix Calculus, Wiley-Interscience, New York
- Athans M.F., Shweppe F.C., (1965), Gradient Matrices and Matrix Calculations, Lincoln Lab., M.I.T., Lexington, Mass
- Marsaglia G. (2006). Ratios of Normal Variables. Journal Od Statistical Software, 16(4), [ http://www.jstatsoft.org/]
________________________________



